Caching Strategies
Substation supports multiple caching deployment patterns by combining conditions, external enrichment processors, and sinks.
Application-Level Caching
All of the caching strategies described on this page can be implemented in any Substation application by using the AWS DynamoDB key-value store.
Distributed Cache
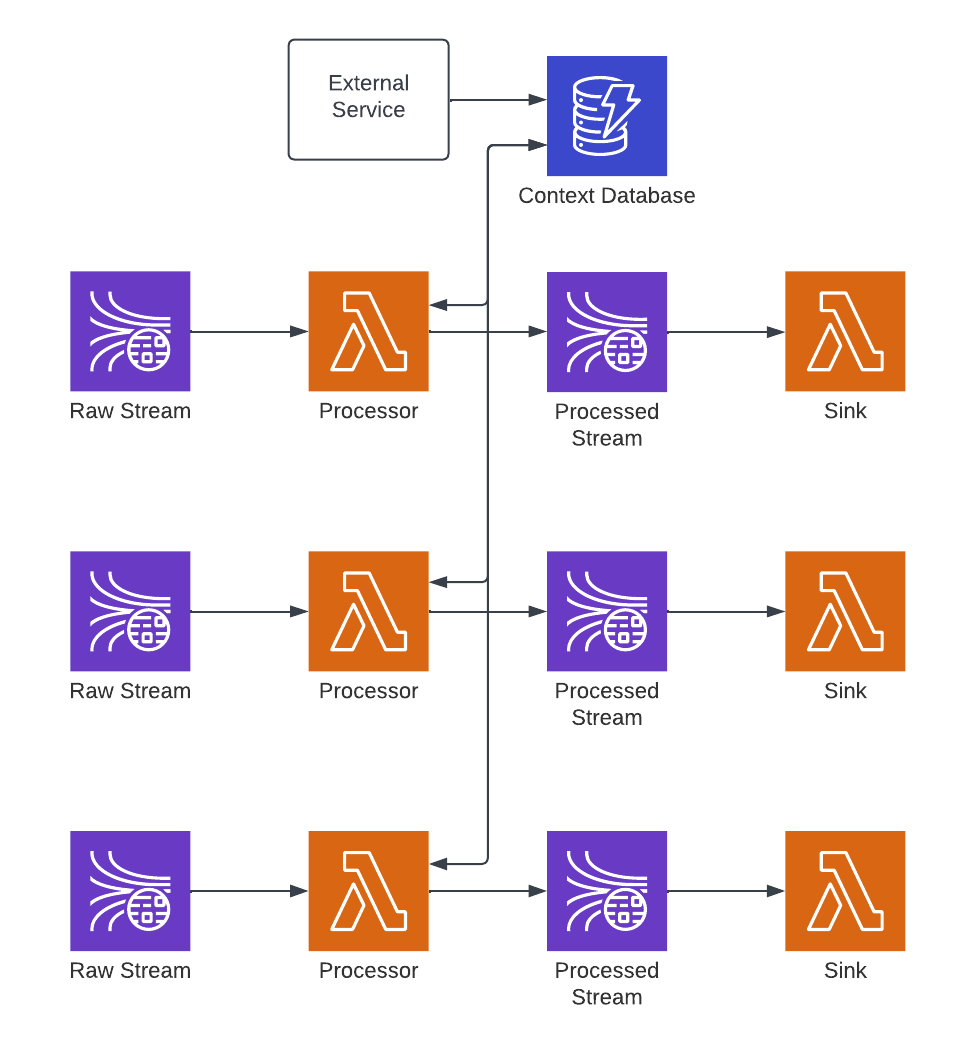
The distributed cache is implemented by connecting one or more Substation applications, usually spread across multiple pipelines in a single deployment, to a database. In this example, processors enrich data from a DynamoDB context database that is fed by an external service:
Self-Updating Cache
The self-updating cache is similar to a distributed cache, except the pipeline reads and feeds the cache using a cache aside pattern. In this example, a processor enriches data from a DynamoDB context database that is fed by a sink from the pipeline:
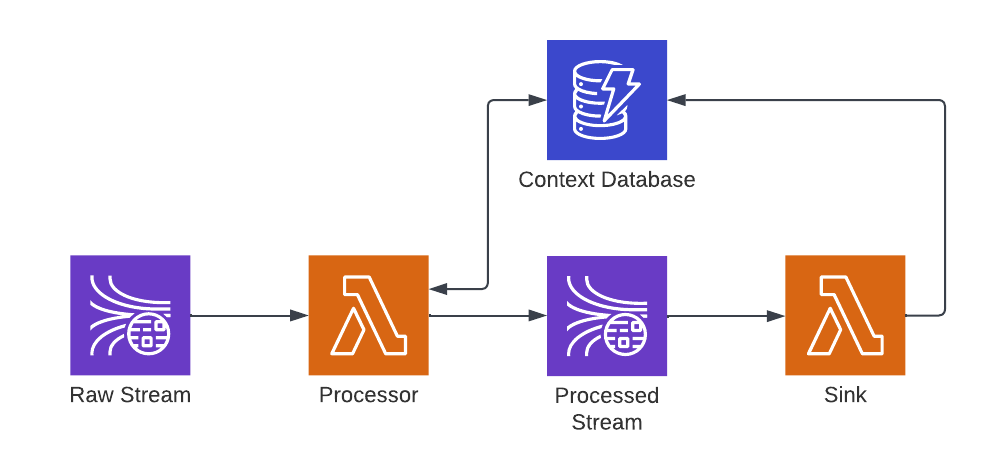
With this design it is important to avoid unnecessary writes to the cache -- the processor should store the results of the cache attempt (hit or miss) in each object and conditionally sink data if the attempt was a miss.
Cross-Pipeline & Cross-Dataset Enrichment
Cross-pipeline and cross-dataset enrichment is possible by combining the distributed cache and self-updating cache patterns:
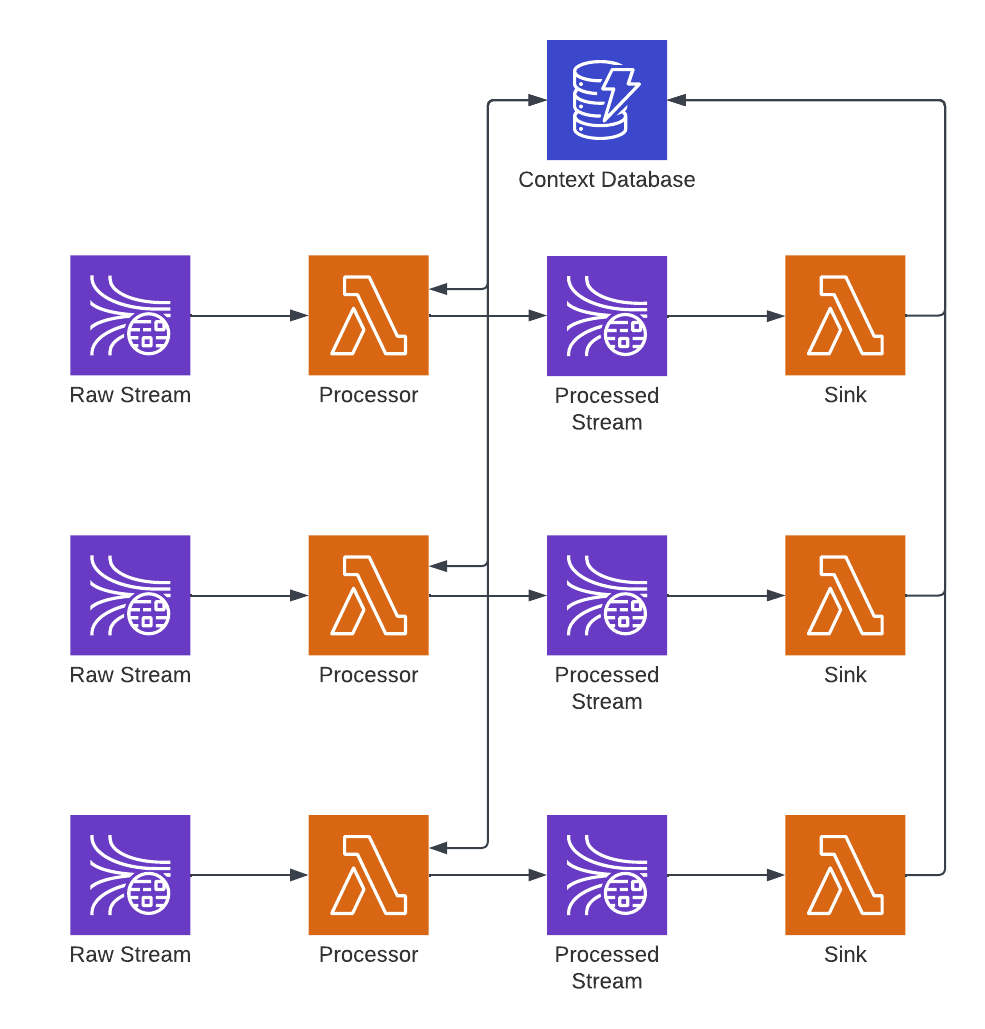
With this pattern any pipeline can enrich its data with information generated in other pipelines in near real-time.
Updated over 3 years ago