Architecture & Design
Substation is built on:
- Go (applications, conditions, processors, sinks)
- AWS (serverless cloud services)
- Jsonnet (configurations as code)
- Terraform (infrastructure as code)
Data Pipelines
Infrastructure as code allows users to build hundreds of unique data pipelines, including these examples:
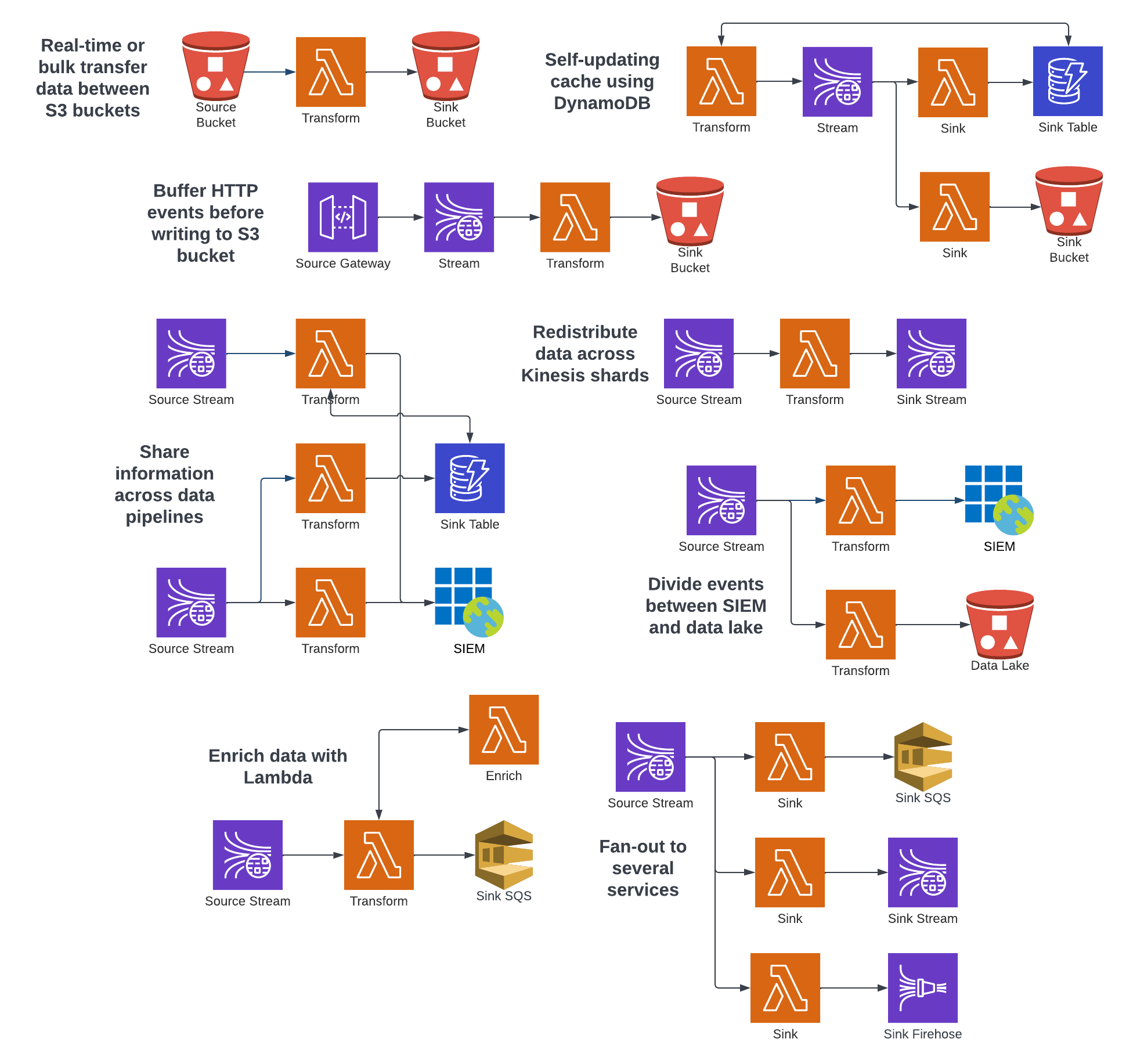
Use this recipe as a guide for deploying AWS pipelines:
Microservices
For users who don't need a data pipeline but still want to transform data, the system can also be deployed as synchronous or asynchronous microservices -- this is the best way to integrate with external systems and users.
Use this recipe as a guide for deploying a synchronous microservice:
Applications
Event-driven ingest, transform, load (ITL) applications process data per-item and in series using this model:
- On startup, the application loads a configuration and creates several concurrent threads to ingest, transform, and load data
- Threads are started in reverse order: load, transform, and ingest
- Data is shared across threads using a pipeline pattern
- Errors in any thread, including the main thread, interrupt the application and return an error
- Data is ingested and each item is sent in the pipeline to one or more transform threads
- Transform threads evaluate and process data in series by checking for success conditions, applying processors, and sending data in the pipeline to a single load thread
- Load thread delivers data to an external destination by using a sink
The AWS Lambda application provides ITL for data pipelines and microservices.
Packages
Conditions, processors, and the ability to build custom Substation applications are provided as Go packages. These are configured using configurations as code and accessed through functions that implement factory patterns.
Use these recipes as a guide for using the Go packages:
Updated over 3 years ago